Kafka 의 동작 방식
주요 개념
Kafka 의 동작 방식에는 주요한 개념이 존재합니다.
주요 개념을 한 가지씩 알아보겠습니다.
Producer & 컨슈머의 분리
카프카의 Producer와 Consumer는 완전 별개로 동작합니다. Producer는 브로커의 토픽에 메세지를 카프카 게시하기만 하고 Consumer는 브로커의 특정 토픽에서 메세지를 가져와 처리하기만 합니다.
Push &Pull
카프카 클러스터를 중심으로 Producer 와 컨슈머가 데이터를 push & pull 하게 됩니다.
Producer와 Consumer는 각기 다른 프로세스에서 비동기로 동작하며 Consumer는 풀 모델을 기반으로 메세지 처리를 진행하는데 Consumer 가 필요시 브로커로부터 메세지를 가져와 처리하는 형태로 효율적인 자원 관리가 가능합니다.
Commit & Offset
컨슈머의 poll()은 이전에 commit 한 오프셋이 존재하면 해당 오프셋 이후 메세지를 읽어옵니다.
읽어온 뒤 마지막 offset 을 commit하고 이어서 poll() 이 실행되면 방금 전 commit 한 offset 이후의 메시지 읽어와 처리하고 제일 처음 접근이거나 오프셋이 없는 경우 auto.offset.reset 옵션을 사용합니다.
offset 에 대한 옵션은 아래와 같이 3가지가 존재합니다.
- earliest : 맨 처음 오프셋 사용
- latest : 가장 마지막 오프셋 사용 ( 기본 옵션 )
- none : 오프셋 정보가 없다면 익셉션 발생
Consumer group
하나의 토픽을 구독하는 여러 컨슈머의 모음입니다.
컨슈머들을 그룹화하는 이유는 가용성 때문인데 하나의 토픽을 처리하는 컨슈머가 하나인 것 보다 여러 개라면 당연히 가용성은 증가될 것인데요. 그룹의 각 컨슈머들은 하나의 토픽의 각기 다른 파티션의 내용만을 처리하는데 이를 통해 카프카는 메시지 처리 순서를 보장합니다.
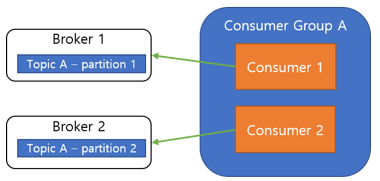

Rbalance
리발란스의 개념은 특정 파티션에서 처리하던 컨슈머가 처리불가 상태가 되면 파티션과 컨슈 머를 재조정하여 그룹 내의 나머지 컨슈머들이 파티션을 적절하게 나누어 처리하도록 하는 것인데요.
그룹 내의 컨슈머들 간에 오프셋 정보를 공유하고 있어 특정 컨슈머가 처리 불가 상태가 되었을 때 해당 컨슈머가 처리한 마지 막 오프셋 이후부터 처리 가능하며 이를 위해서 컨슈머 그룹이 필요합니다.
Scalability
컨슈머의 확장성을 의미합니다.
컨슈머의 성능이 부족해 확장할 경우 컨슈머만을 확장하면 당연히 새 컨슈머는 놀게 되기 때문에 컨슈머 확장 시에는 파티션도 함께 늘려줘야 합니다. 하지만 파티션은 한번 늘리면 줄일 수 없음으로 주의가 필요합니다.
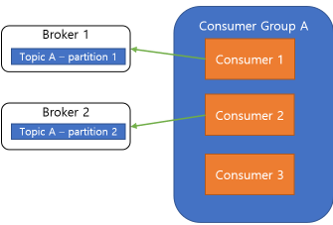

동작 원리
컨슈머는 지속적으로 Heart Beat 를 전송해 연결을 유지합니다.
브로커는 일정 시간 컨슈머로부터 하트비트가 없으면 컨슈머를 그룹에서 빼고 리밸 런싱을 진행하며 하트비트의 간격은 사용자가 지정할 수 있습니다.
프로듀서는 일정 크기만큼 메세지를 모아서 전송이 가능하고 컨슈머는 최소 크기만큼 메세지를 모아 조회가 가능합니다. 해서 낱개 처리보다 처리량이 증가될 수 있습니다.
처리 과정은 아래와 같습니다.
- send()메소드를 이용 데이터 전송
- Serializer 이용 배열로 변환
- Partitioner 이용 파티션 결정
- 변환된 바이트배열 (메세지) 버퍼에 저장하여 배치로 묶어 처리량을 증가
- sander 이용 배치를 차례대로 가지고와 차례대로 브로커에게 배치 전송 배치가 찼는지 개수 여부와 상관없이 브로커에 전송하며 샌더는 별도 스래드로 동작
- sander 가 배치를 보내는 동안 snad() 매소드로 들어온 메세지들은 배치에 누적
배치와 샌더가 서로 다른 스레드로 동작하기 때문에 두 항목에 대한 설정이 처리량에 영향을 미치게 됩니다.
이벤트 전달 방식에는 아래와 같은 방식들이 있습니다.
- at most once( ) 최대 한 번 : 메시지 손실 가능성 있지만 재전달 하지 않음
- at least once ( ) 최소 한 번 : 메시지가 손실되진 않지만 재전달 함
- exactly once ( ) 정확히 한 번 : 메시지는 정확하게 한 번 전달됨
만약 전송이 실패했을 경우에는 두 가지 대처 방법이 존재하는데요
'재시도' 혹은 '추후 처리를 위한 기록'입니다.
재시도는 sand() 메서드에서 예외 발생 시 예외 타입에 따라 메서드를 재호출 합니다.
추후 처리를 위한 기록 방법은 별도의 파일 혹은 DB 등에 실패한 메시지를 기록하고 추후에 보정 작업을 진행합니다.
'Big Data > Apache Kafka' 카테고리의 다른 글
| Apache Kafka 란? (0) | 2022.12.06 |
|---|
