프로세스와 운영체제
운영체제, 다른 말로 프로세스 관리자는 이름 그대로 프로세스를 관리하는 역할을 합니다.
아래 세가지 역할을 수행합니다.
- 프로세스의 생성 및 종료
- 프로세스의 실행을 위한 스케줄링 작업
- 프로세스의 상태 관리
프로세스의 생성과 종료
프로세스의 생성
프로세스 생성 방법은 크게 두 가지입니다.
1. 사용자가 프로그램을 직접 실행
2. 한 프로세스가 다른 프로세스 생성 (프로세스 생성 시스템 호출 이용)
시스템 호출은 사용자모드에서 자원 할당이 필요하여 커널모드로 변경 시 사용되는 호출이라고 설명한 적이 있습니다.
두 번째 상황에서 시스템 호출을 하는 프로세스를 부모 프로세스, 시스템 호출을 통해 새로 만들어진 프로세스를 자식 프로세스라고 합니다.
부모프로세스도 부모프로세스가 존재할 수 있습니다.
부모의 부모로 계속 거슬러 올라가다 보면 최초의 프로세스(운영체제 기동 등)가 존재합니다.
모든 프로세스는 그 최초의 프로세스에서 트리 형태로 생성됩니다.
프로세스 생성 시스템 호출
UNIX / LINUX : fork() & exec()
fork()
pid = fork();위와 같이 프로세스를 생성합니다.
해당 명령어는 부모프로세스를 복제하여 자식프로세스를 생성하는데요.
부모를 복제하여 생성한 프로세스이기 때문에 코드, 데이터, PBC 등을 모두 복제합니다.
오직 PID 만 변경됩니다.
해당 명령어는 PID를 반환하는데 부모프로세스에게는 자식의 프로세스 아이디를, 자식프로세스라면 0이 반환됩니다.
해서 부모 / 자식 프로세스를 구분할 수 있습니다.
exec()
자식 프로세스에게 다른 일을 시키고 싶을 때 사용하는 명령어입니다.
pid = fork();
if(pid == 0)
exec(program2)새로운 프로세스를 생성하는 것이 아닌 exec()를 호출한 프로세스를 새로운 프로세스로 덮어씁니다.
호출한 프로세스의 PID는 그대로 새로운 프로세스에 적용됩니다.
해서 코드와와 메모리 PCB 모두 program2의 값으로 변경되지만 PID 만 바뀌지 않습니다.
Windows : CreateProcess
윈도우즈의 경우 CreateProcess명령어를 통해 생성합니다.
자식 프로세스는 처음부터 새로운 프로세스로 생성되며 프로그램, PID 값 등을 인자로 전달하며 호출합니다.
자식 프로세스는 처음부터 program2에 대한 프로세스로 만들어집니다.
프로세스의 종료
정상적 종료
프로세스의가 모든 처리를 완료한 뒤 스스로 종료되는 경우입니다.
강제적 종료
1. 부모프로세스에 의해 자식 프로세스가 강제로 종료
자식 프로세스 생성 시 얻은 자식의 PID 이용 프로세스 종료 시스템 호출을 이용합니다.
2. 부모프로세스에 종료되는 경우 운영체제가 자식 프로세스 종료
프로세스의 상태
프로세스는 생성, 준비, 실행, 대기, 종료의 다섯 상태 중 하나로 존재한다고 말씀드렸죠?
조금 더 자세히 알아보겠습니다.
생성
프로그램 더블클릭 시 프로세스 생성을 위해 처리되는 작업으로 처음 작업이 시스템에 주어진 상태입니다.
먼저 프로세스를 위한 메모리 구조를 생성합니다.
코드 영역에 코드를 올리고 데이터 영역에 데이터를 준비합니다.
프로세스를 관리할 PBC 도 생성하며 PID를 만들고 상태정보를 할당합니다.
메모리와 PCB 등이 모두 준비가 되었다면 준비상태로 변경합니다.
준비
실행 준비가 되어 CPU 할당을 기다리는 상태입니다.
준비 큐라는 개념이 존재하는데요.
준비 큐에는 여러 프로세스들이 들어와 있습니다.
자신의 차례가 되면 실행상태로 전환하게 됩니다.
실행
프로세스가 처리되는 상태로 프로그램의 명령어들을 수행합니다.
대기
프로세스가 I/O 작업이 끝날 때까지 또는 특정 자원을 할당받을 때까지 보류되는 상태입니다.
해당 상태에서 기다리는 동안 CPU 를 잡고 있으면CPU 가 낭비되겠죠?
그때 대기상태로 전환 후 CPU를 다른 프로세스에게 양보하고 대기상태로 기다리게 됩니다.
종료
종료는 프로세스가 더 이상 실행되지 않도록 끝난 상태를 말합니다.
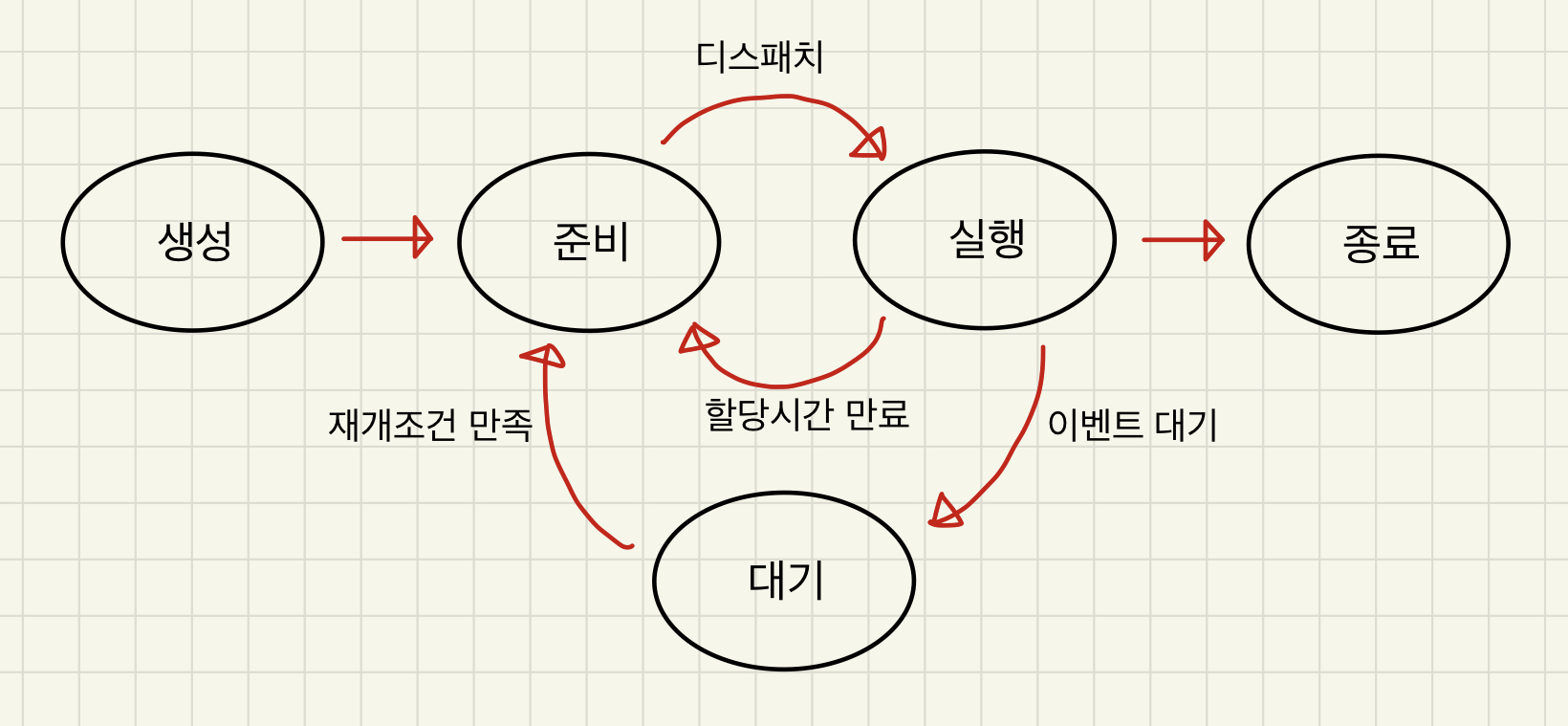
프로세스의 상태 변화
프로세스의 상태는 생성에서 종료로, 종료에서 실행으로 마구 변화될 수 없습니다.
변화될 수 있는 상태가 정해져 있는데요.

1. 생성 -> 준비
생성에서는 준비로만 변화될 수 있습니다.
2. 준비 -> 실행
디스패치라고 합니다.
프로세스에 CPU를 할당하여 작업을 실행하는 작업 자체를 디스패치라고 말합니다.
3. 실행 -> 준비
할당시간 만료 시 준비상태로 돌아갈 수 있습니다.
또는 우선순위가 높은 프로세스가 준비 큐에 들어와 나의 CPU를 그 프로세스에 디스패치하는 상황이 생긴 경우에도 준비상태로 돌아갑니다.
4. 실행 -> 대기
이벤트 대기 상황에서 전환됩니다.
프로세스의 자의에 의해(필요 작업 수행 중) 스스로 CPU를 반환 후 대기합니다.
5. 대기 -> 준비
대기하던 이유가 끝난 경우(입출력 종료, 페이지 교체 종료 등), 즉 재개 조건 만족 시 대기에서 준비 큐로 들어가게 되고 디스패치되어 실행됨을 반복합니다.
6. 실행 -> 종료
프로그램의 오류 혹은 부모 프로세스가 종료 등 다양한 이유로 변화됩니다.
정리하자면 아래와 같습니다.
스레드(Thread)
하나의 프로그램을 실행하기 위한 기본적인 단위입니다.
그건 프로세스 아니냐고요?
전통적인 프로세스 개념에서 프로세스는 하나의 프로그램을 실행하기 위한 기본적인 단위를 뜻했습니다.
또한 자원소유(메모리 구조)와 디스패칭의 단위이기도 했죠.
위에서 디스패칭은 CPU를 할당받아 명령어를 처리하는 작업이라고 말씀드렸습니다.
프로세스는 PC값으로 다음 실행 명령어를 가지고 있으며 하나의 제어 흐름의 단위가 되었습니다.
다만 PC는 다음 명령어 하나만 가지고 있어 다중처리가 불가능했습니다.
이런 불편을 개선하기 위해 스레드라는 개념이 등장했습니다.
프로세스 내에서 다중처리를 위해 제안된 개념으로 프로세스에 여러 개의 PC 존재하게 됩니다.
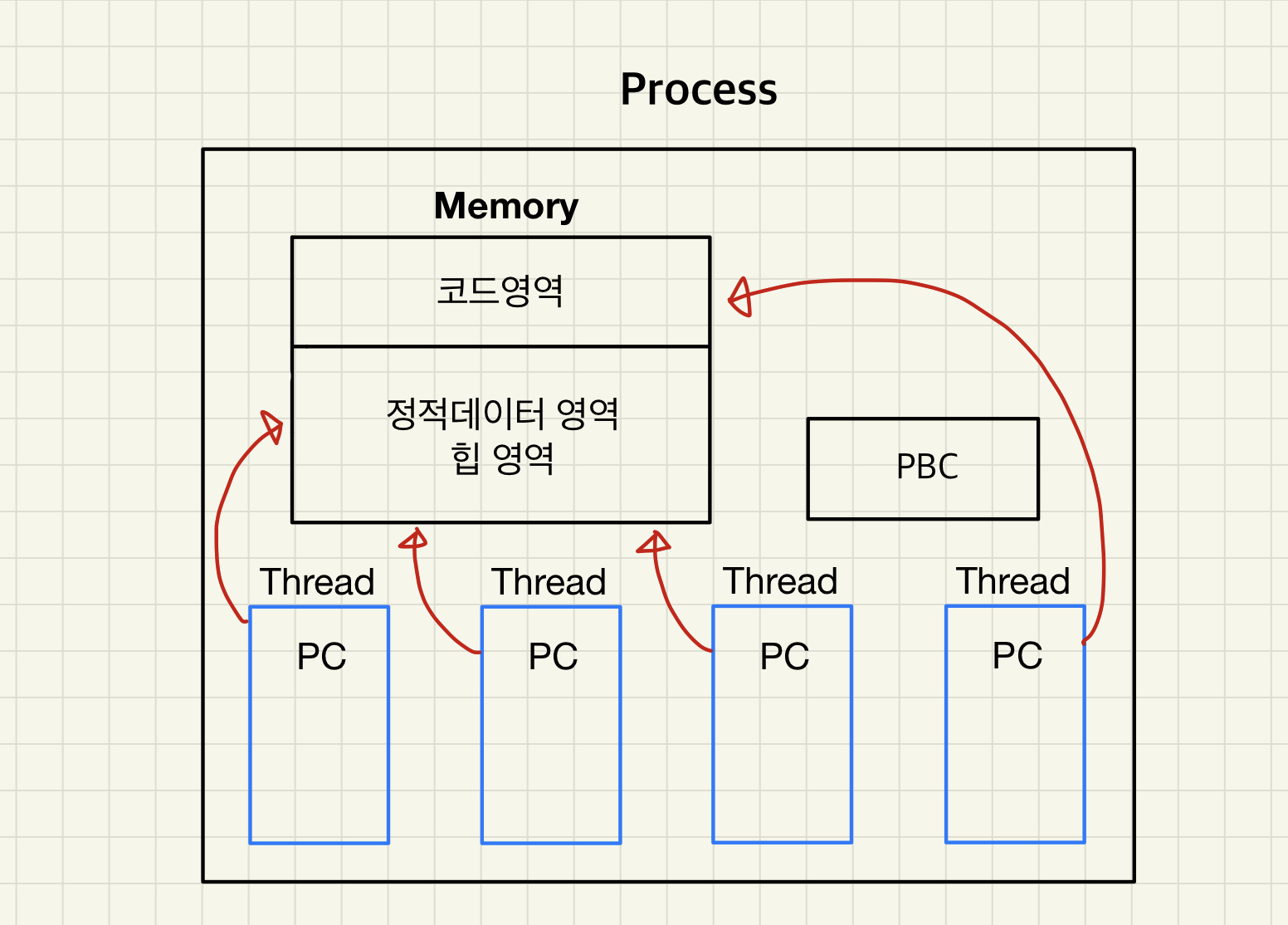
어떻게 가능할까요?
하나의 프로세스에는 하나 이상의 스레드가 존재합니다.
스레드의 등장으로 하나의 프로그램을 실행하기 위한 기본적인 단위가 프로세스에서 스레드로 내려왔습니다.
해서 스레드는 디스패칭의 단위가 되었습니다.
하지만 자원은 여전히 프로세스 단위로 할당되기 때문에 자원소유의 단위는 여전히 프로세스입니다.
쓰레드는 실행에 필요한 최소한의 정보만 갖습니다.
- PC를 포함한 레지스터 값
- 상태 정보
- 스택
스레드마다 PC 정보를 가지고 있어 스레드별로 제어됩니다.
스레드마다 실행이 다르기 때문에 서브프로그램의 호출 과정이 다를 수 있습니다.
해당 과정을 위한 정보들이 다르기 때문에 스택 영역이 별도로 존재하여 쓰레드별로 관리합니다.
위의 세 가지 정보 외에는 프로세스에 두고 다른 스레드와 공유합니다.
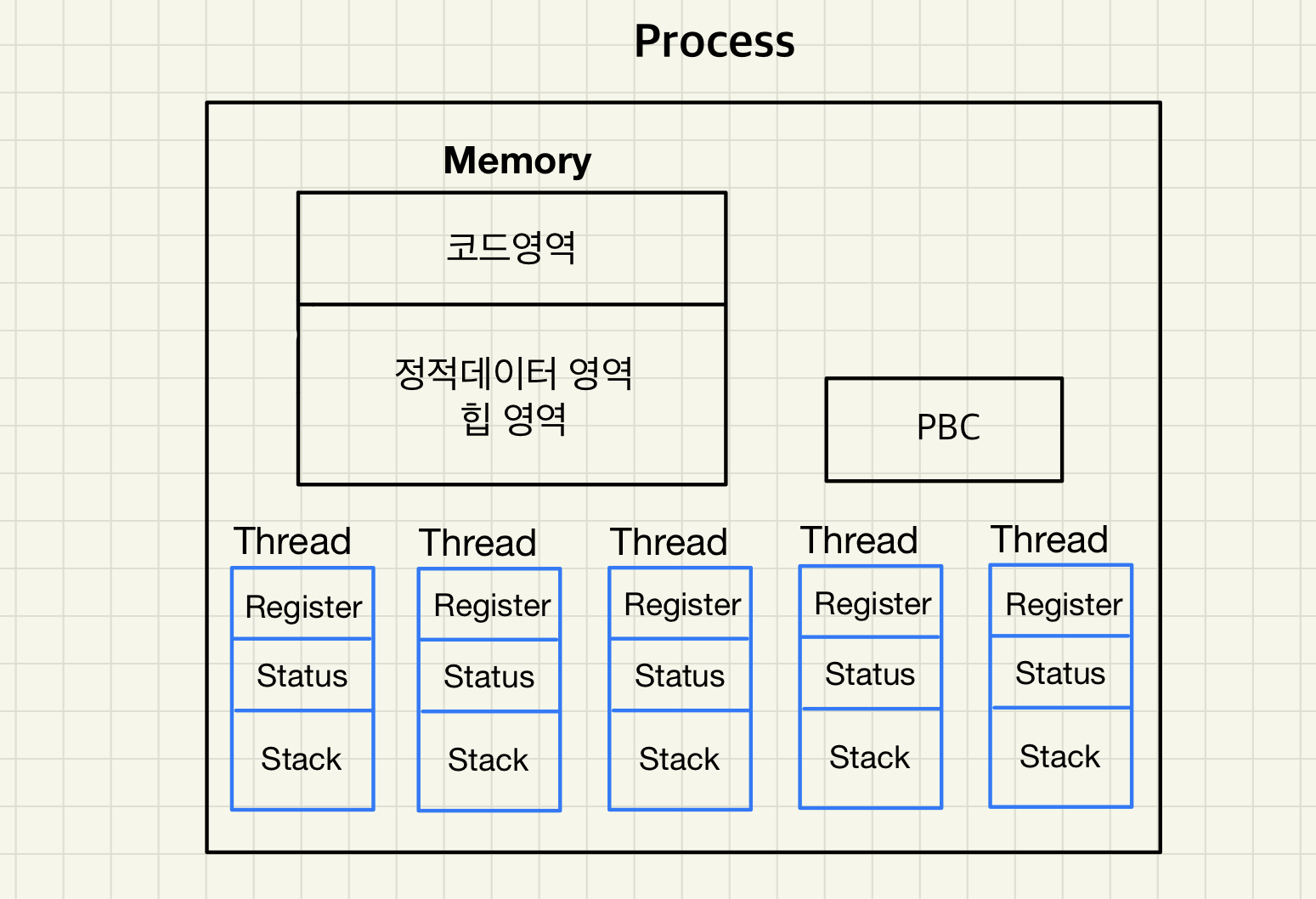
다중 스레드로 구성된 프로세스
Multi CPU / Mulit Core Computer System 환경에서는 다중 스레드를 병렬로 처리가 가능하여 프로그램의 효율이 상승합니다.
CPU 가 하나밖에 없더라도 스레드가 용도별 / 처리 속도 별로 나눠진 경우 효율적인 처리가 가능합니다.
예를 들어 입력, 출력, 계산용 스레드가 나누어져 있다면 계산용 스레드가 대부분의 자원을 사용하고 중간중간 입력 / 출력 스레드에 CPU를 빌려주는 방식으로 효율적 처리가 가능합니다.
'Computer Science > OS' 카테고리의 다른 글
| [OS] 병행프로세스 (0) | 2023.04.17 |
|---|---|
| [OS] 프로세스 스케줄링 알고리즘 (0) | 2023.03.15 |
| [OS] 프로세스 스케줄링 (0) | 2023.03.13 |
| [OS] 프로세스란? (0) | 2023.03.05 |
| [OS] 운영체제 개요 (0) | 2023.02.26 |



